在前两篇关于神经网络工程基础的文章中,我们讨论了网络架构的设计原则与数据处理的关键技术。本篇作为系列文章的第三部分,将聚焦于驱动神经网络学习的核心引擎——最优化算法。承接网络工程实践,我们深知,一个精心设计的模型若缺乏高效的优化策略,其潜能将难以充分发挥。
一、优化算法的重要性与挑战
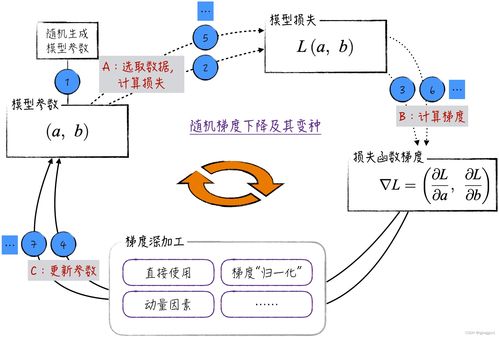
神经网络的训练本质上是一个在超高维参数空间中寻找最优解(或满意解)的过程。这个“最优”通常指使损失函数值最小化的一组参数。由于现代网络的参数量动辄百万甚至千亿,且损失函数地形复杂(非凸、存在大量鞍点和平坦区域),传统的优化方法往往力不从心。因此,专门为神经网络设计的优化算法成为了工程实践中的关键。
二、梯度下降的演进:从SGD到自适应方法
- 随机梯度下降(SGD)及其变种:作为最基本的优化器,SGD每次更新仅使用一个或一小批(Mini-batch)样本的梯度。虽然简单,但其更新方向噪声大,容易在沟壑中震荡,收敛速度慢。为此,引入了动量(Momentum) 方法,它通过累积历史梯度的指数移动平均来加速在相关方向的收敛,并抑制震荡,宛如给下山的小球增加了惯性。
- 自适应学习率算法:这类算法的核心思想是为每个参数赋予独立的自适应学习率。
- AdaGrad:为频繁更新的参数减小步长,为不频繁更新的参数增大步长,适合处理稀疏数据。但其学习率可能过早、过度地衰减。
- RMSProp 与 AdaDelta:它们通过引入指数衰减平均来改进AdaGrad,解决了学习率单调递减过快的问题,只关注最近一段时间的梯度幅度。
- Adam(Adaptive Moment Estimation):目前最流行、默认推荐尝试的优化器之一。它结合了动量(一阶矩估计)和RMSProp(二阶矩估计)的思想,并进行了偏差校正。Adam通常能提供快速且相对稳定的收敛,对超参数(除学习率外)不那么敏感,成为许多工程项目的首选起点。
三、现代优化策略与工程考量
- 学习率调度(Learning Rate Scheduling):动态调整学习率比使用固定值更为有效。常见策略包括:
- 阶梯下降:在预设的轮次将学习率乘以一个衰减因子。
- 余弦退火:模拟余弦函数从初始值缓慢衰减到0,有时会配合周期性重启以跳出局部最优点。
- 热身(Warm-up):在训练初期使用较小的学习率,逐步提升到预设值,有助于稳定训练初期的不确定性。
- 梯度裁剪(Gradient Clipping):尤其在训练循环神经网络(RNN)时,梯度爆炸是常见问题。通过设定阈值,对梯度向量的范数进行裁剪,能有效保证训练稳定性。
- 优化器选择实践指南:
- Adam 通常是良好的默认选择,尤其在处理大数据、深度网络和非平稳目标时表现优异,收敛速度快。
- 带动量的SGD(如SGD with Nesterov Momentum)在经过精细调优(特别是学习率调度)后,最终可能达到比Adam更优的泛化性能,尤其在计算机视觉等经典领域,但需要更多的超参数调试成本。
- 对于稀疏数据或需要动态调整学习率的场景,RMSProp及其变体值得考虑。
四、超越一阶优化:二阶方法浅析
尽管一阶方法(仅使用梯度)主导了深度学习,但二阶方法(使用梯度和海森矩阵信息)理论上收敛更快。由于直接计算海森矩阵及其逆的代价过高,出现了如拟牛顿法(L-BFGS)等近似方法。对于深度神经网络的大规模、非凸优化问题,以及小批量训练带来的噪声,经典二阶方法往往不如自适应一阶方法鲁棒和高效。一些研究工作致力于开发适用于深度学习的可扩展二阶优化器,但仍处于探索阶段。
算法、架构与数据的协同
最优化算法是神经网络工程化落地的关键一环。没有“放之四海而皆准”的最优算法,只有与具体任务、网络架构、数据特性相匹配的合适选择。在实践中,工程师往往以Adam等现代优化器为起点,结合精细的学习率调度、权重初始化、正则化策略以及充分的数据准备,共同构成一个稳定、高效、泛化能力强的训练管道。
在下一篇文章中,我们将探讨神经网络工程化的另一个支柱:正则化与泛化技术,看看如何让我们的模型不仅学得快,更能学得好,在未见数据上表现出强大的推理能力。